
Building a Music Genre Classifier That Actually Understands Sound
Published:
After 18 years of pursuing music, I’ve developed an ear for what makes genres distinct. It’s not just the obvious markers—tempo, instrumentation, vocal style. It’s the subtle stuff: the way tension builds in a Carnatic raga versus a jazz standard, the textural differences between layered synthesizers in electronic music versus acoustic instruments in folk, the non-linear patterns that define a sound but resist simple categorization.
Traditional neural networks miss this. And I think I know why.
The Problem with Standard Approaches
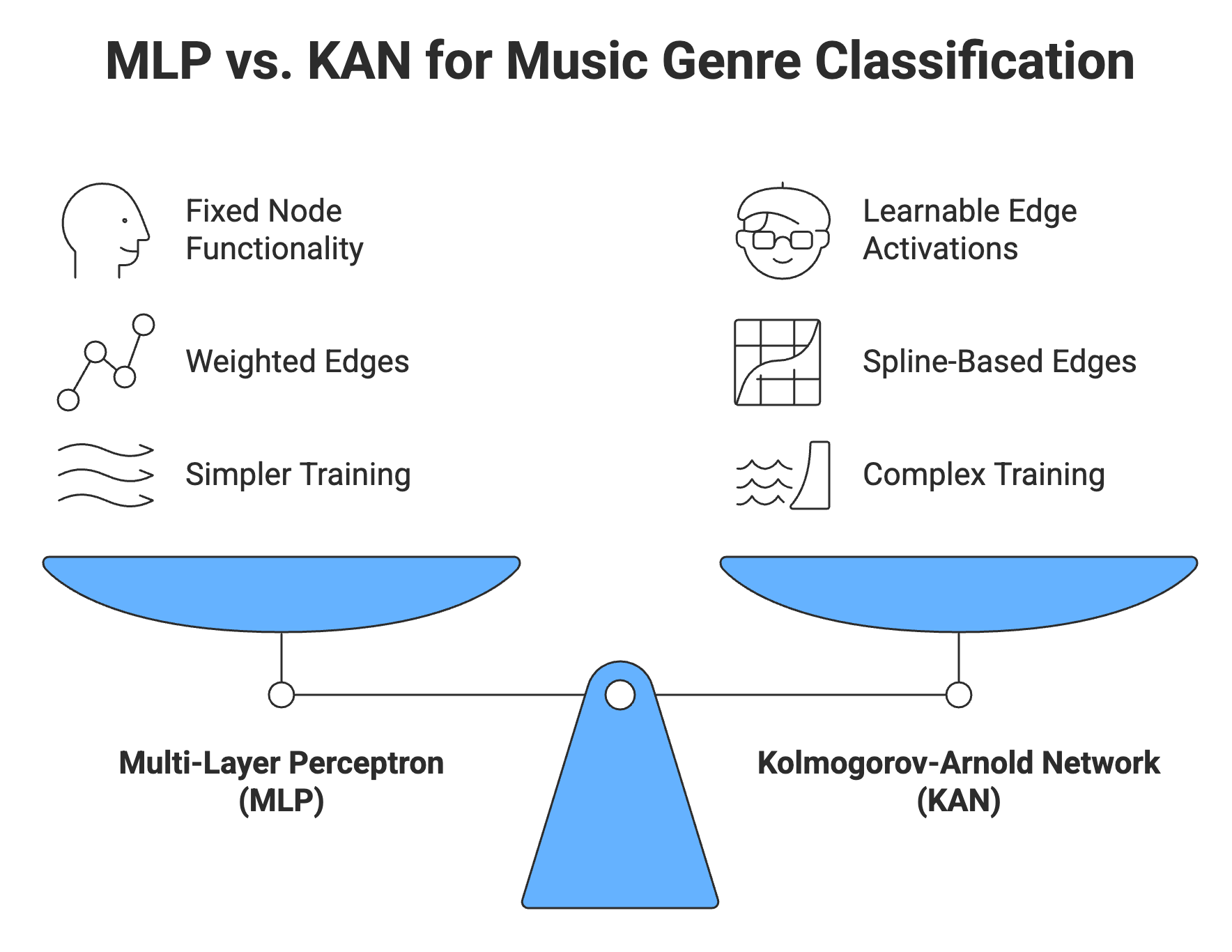
Most audio classification models use Multi-Layer Perceptrons (MLPs) with fixed activation functions like ReLU or sigmoid. These architectures are elegant in their simplicity: neurons apply predetermined transformations to weighted inputs, stacking layers to build increasingly complex representations.
For many tasks, this works brilliantly. They’re fast to train, well-understood, and backed by robust optimization techniques. But music—especially genre classification—presents unique challenges that fixed activation functions struggle with.
The core issue: Music’s defining characteristics often lie in non-linear spectral relationships that don’t map cleanly to standard activation patterns. The interplay of harmonics, the evolution of timbre over time, the complex modulations that differentiate a blues guitar from a metal guitar playing the same note—these require adaptive, learnable transformations that fixed functions can’t provide.
Enter Kolmogorov-Arnold Networks
This is where Kolmogorov-Arnold Networks (KANs) become interesting. Unlike MLPs, which apply fixed activation functions at nodes, KANs learn their activation functions using splines on the edges of the network.
What this means practically:
MLPs: Fixed node functionality + Weighted edges + Simpler training KANs: Learnable edge activations + Spline-based edges + Complex training
The network doesn’t just learn weights—it learns the shape of the transformations themselves. For audio, this is powerful. Instead of forcing spectral features through predetermined activation patterns, the network adapts its internal representations to whatever transformations best capture the underlying structure of the sound.
Specialized variants like Interpretable Convolutional KANs (ICKANs) are hitting 95%+ classification accuracy on genre tasks, significantly outperforming comparable MLPs. They’re particularly effective at modeling the complex spectral features that define musical genres—the subtle harmonic relationships, temporal dynamics, and textural qualities that traditional networks miss.
The Speed Problem
Here’s the catch: KANs train nearly 10x slower than MLPs.
For a research project or a one-off model, this is manageable. But for platforms like Spotify processing millions of tracks, or any production system that needs to retrain frequently, this speed penalty is prohibitive. The computational overhead of learning spline-based activation functions across every edge in the network compounds quickly.
Additionally, hardware acceleration for KANs is still in its infancy. The optimization techniques, specialized chip architectures, and distributed training frameworks that make standard deep learning fast and efficient haven’t caught up to KAN architectures yet. We’re working with tools built for a different paradigm.
My Approach: Few-Shot Learning + ICKANs
Rather than accepting the speed trade-off or waiting for infrastructure to evolve, I’m experimenting with a different strategy: pairing ICKANs with Few-Shot Learning.
The logic:
If the model can generalize effectively from significantly fewer training examples, we offset the per-epoch training cost. Instead of needing thousands of examples per genre to achieve high accuracy, a few-shot approach might achieve comparable performance with dozens.
This addresses both the computational problem and the infrastructure problem:
- Computational: Fewer training examples × 10x training time per epoch = manageable total training time
- Infrastructure: We work around current hardware limitations rather than waiting for specialized KAN acceleration
Few-Shot Learning fundamentals:
Few-shot learning frameworks like Prototypical Networks or Model-Agnostic Meta-Learning (MAML) train models to learn from minimal examples by optimizing for rapid adaptation. Instead of memorizing specific training data, they learn generalizable representations and comparison strategies that transfer across tasks.
For music genre classification, this is particularly relevant. Genres exist on a spectrum, share characteristics, and constantly evolve. A model that learns how to identify genre distinctions rather than memorizing specific genre patterns should generalize better to new music, emerging subgenres, and edge cases.
Early Experiments
I’m currently working through initial experiments on a subset of the GTZAN dataset, focusing on a few-shot learning framework with ICKAN as the embedding network.
Preliminary approach:
- Preprocessing: Extract mel-spectrograms from audio clips (standard representation for audio ML)
- Embedding Network: ICKAN architecture processes spectrograms into learned representations
- Few-Shot Framework: Prototypical Networks for episode-based training
- Evaluation: N-way K-shot classification (e.g., 5 genres, 5 examples each)
Early observations:
The ICKAN embeddings appear to capture more nuanced spectral patterns than comparable MLP baselines, even with limited training data. Cross-genre confusion is lower, particularly for genres with subtle distinctions (e.g., jazz vs. blues, classical vs. instrumental).
Training time is still higher than MLPs, but the few-shot framework keeps total training time reasonable. More importantly, the model shows promising generalization to genres with very few training examples—exactly the scenario where traditional supervised learning struggles.
Why This Matters
Building ML systems for music isn’t just an academic exercise for me. Music has been central to my life for nearly two decades—from learning Carnatic classical music to exploring how machine learning can capture what makes music meaningful.
Standard ML approaches treat audio as just another signal to classify. But music is fundamentally about nuance, context, and subjective interpretation. A truly effective music understanding system needs to capture this complexity, not just pattern-match on surface features.
KANs, with their learnable activation functions, offer a path toward models that adapt to music’s inherent structure rather than forcing it into predetermined representations. Few-shot learning offers a path toward systems that generalize like humans do—learning concepts from limited exposure rather than requiring exhaustive training data.
This sits at the intersection of two things I care deeply about: music and machine learning. It’s exactly where I want to be building.
Next Steps
Immediate priorities:
- Expand dataset diversity: Beyond GTZAN to more contemporary genres and edge cases
- Ablation studies: Systematically compare ICKAN vs. standard KAN vs. MLP baselines
- Optimization experiments: Explore whether pruning or quantization can further reduce training costs
- Real-world testing: Evaluate on out-of-distribution music (live recordings, amateur productions, cross-cultural genres)
Longer-term questions:
- Can few-shot KANs enable personalized genre models (adapting to individual listening preferences)?
- How do these architectures perform on other audio tasks (instrument recognition, mood classification, similarity metrics)?
- What happens when we apply this to multimodal inputs (audio + lyrics + metadata)?
Technical Implementation
Current Stack:
- Python 3.x for implementation
- PyTorch for model architecture
- torchaudio for audio preprocessing
- librosa for feature extraction
- NumPy & SciPy for signal processing
Key Resources:
- GTZAN Genre Classification Dataset
- Prototypical Networks framework
- ICKAN implementation based on recent KAN research
This work is ongoing. If you’re working on similar problems at the intersection of audio ML and novel architectures, I’d love to connect and exchange ideas.